Dataset
Technical Details
The Dataset Service works with datasets instead of a single file The Dataset service requires that OSDU Data Platform’s services are registered per dataset schema type. E.g.: ‘dataset–File.’ -> Service 1, ‘dataset–FileCollection.’ -> Service 2. This services defines the workflows to upload and retrieve source files and register metadata
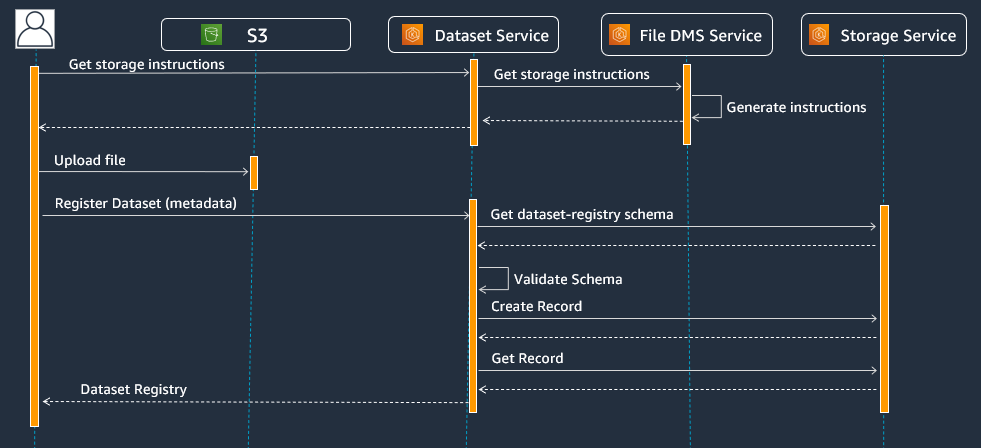
This lab illustrates uploading and registering of a file into the OSDU platform
Registering in OSDU is a three step process
- Step 1: Get the S3 credentials and bucket path needed for the upload
- Step 2: Upload the file to S3 using the credentials
- Step 3: Create and register a new Dataset entity for the newly uploaded S3 file
| Objective | Upload and Register a new file into the OSDU platform |
|---|---|
| APIs | /api/dataset/v1/ |
| Security | Cognito using UserID & Password |
Lab
Create a new Python file
Open the DataSet.py in your text editor
Import required libraries
Import the following required libraries into your Python code:
import boto3
import hmac
import requests
import json
import getpass
import json
import base64
import hashlib
Authenticate against AWS Cognito
# Insert EDI region here
region = ""
# Insert username
user_name=input('Username:')
# Insert password
password=getpass.getpass("Password:")
# Insert client Id
client_id = ""
# Insert client secret
clientSecret=""
# Insert platform URL
osdu_platform_url = ""
# Insert partitiion Id
osdu_partition = ""
# Authenticate against AWS Cognito
cognito = boto3.client('cognito-idp', region_name = region)
# Compute secret hash
message = user_name + client_id
dig = hmac.new(clientSecret.encode('UTF-8'), msg=message.encode('UTF-8'), digestmod=hashlib.sha256).digest()
secretHash = base64.b64encode(dig).decode()
# Attempt to authenticate with the identity provider
access_token = ""
try:
auth_response = cognito.initiate_auth(
AuthFlow="USER_PASSWORD_AUTH",
AuthParameters={"USERNAME": user_name, "PASSWORD": password,"SECRET_HASH": secretHash},
ClientId=client_id,
)
access_token = auth_response["AuthenticationResult"]["AccessToken"]
print("Success! You can now use the OSDU Platform APIs")
except:
print("An error occurred in the authentication process")
headers = {
"Authorization": "Bearer " + access_token,
"Content-Type": "application/json",
"data-partition-id": osdu_partition,
}
Step 1: Retrieve Amazon S3 bucket, path and credentials to upload a file
URL params
Set the kindSubType to a File
params = {
"kindSubType": "dataset--File.Generic"
}
Request storage instructions
These include the accessKeyId, secretAccessKey, sessionToken, the name of the bucket and also the path inside it
# Request storage instructions
osdu_get_storage_instructions_url = osdu_platform_url + '/api/dataset/v1/storageInstructions'
print(osdu_get_storage_instructions_url)
# Query and print result
result = requests.get(osdu_get_storage_instructions_url, params=params, headers=headers)
print(json.dumps(result.json(), indent=4))
Extract bucket and path
unsignedUrl = result.json()["storageLocation"]["unsignedUrl"]
bucket_name = (unsignedUrl.split("//")[1]).split('/', 1)[0]
folder_path = (unsignedUrl.split("//")[1]).split('/', 1)[1]
print("unsignedUrl: " + unsignedUrl)
print("bucket_name: " + bucket_name )
print("folder_path: " + folder_path)
Extract credentials
credentials = result.json()["storageLocation"]["credentials"]
accessKeyId = credentials["accessKeyId"]
secretAccessKey = credentials["secretAccessKey"]
sessionToken = credentials["sessionToken"]
We now have the S3 bucket path and the credentials needed for the upload
Step 2: Upload the files to Amazon S3 using the credentials
Connect to S3 with the credentials
s3 = boto3.client(
's3',
aws_access_key_id=accessKeyId,
aws_secret_access_key=secretAccessKey,
aws_session_token=sessionToken
)
Prepare files for upload to S3
Download the 7552_p0505_1984_comp.las and 7657_d1203s1_1985.las files and place them in the same folder as your Python file.
import os.path
from os import path
print(path.exists("7552_p0505_1984_comp.las"))
print(path.exists("7657_d1203s1_1985.las"))
Ensure that the output is returned as True
Upload files to S3
local_file_name_with_path = '7552_p0505_1984_comp.las'
s3_file_name_with_path = folder_path + '7552_p0505_1984_comp.las'
response = s3.upload_file(local_file_name_with_path, bucket_name, s3_file_name_with_path)
local_file_name_with_path2 = '7657_d1203s1_1985.las'
s3_file_name_with_path2 = folder_path + '7657_d1203s1_1985.las'
response = s3.upload_file(local_file_name_with_path2, bucket_name, s3_file_name_with_path2)
Check to see if it exists in S3
s3.list_objects(Bucket=bucket_name, Prefix=folder_path)['Contents']
Output should be similar to this:
[{'Key': 'osdu/SDb_RTXxcEaR1KX2Ge0p7DMZ6P0/7552_p0505_1984_comp.las',
'LastModified': datetime.datetime(2022, 7, 26, 13, 23, 32, tzinfo=tzlocal()),
'ETag': '"68ff44767fbb41c48eb3ac1b1e5238cb"',
'Size': 1389147,
'StorageClass': 'STANDARD',
'Owner': {'DisplayName': 'bootcamp20220726-1657734095',
'ID': '376d8e7ce82a69185545376aff4f6ae3e7e1bc3c31f3df26cfbcee8cbfe4f493'}},
{'Key': 'osdu/SDb_RTXxcEaR1KX2Ge0p7DMZ6P0/7657_d1203s1_1985.las',
'LastModified': datetime.datetime(2022, 7, 26, 13, 23, 32, tzinfo=tzlocal()),
'ETag': '"22ff675aadfa2ef2ac67743b53a00ad7"',
'Size': 405151,
'StorageClass': 'STANDARD',
'Owner': {'DisplayName': 'bootcamp20220726-1657734095',
'ID': '376d8e7ce82a69185545376aff4f6ae3e7e1bc3c31f3df26cfbcee8cbfe4f493'}}]
Step 3: Create and register a new Dataset entity for the newly uploaded S3 file
fileSource1 = unsignedUrl + "7552_p0505_1984_comp.las"
print(fileSource1)
fileSource2 = unsignedUrl + "7657_d1203s1_1985.las"
print(fileSource2)
Define the Dataset json and specify the full path of our newly uploaded S3 file (above) in the “PreLoadFilePath”
new_dataset = json.dumps({
"datasetRegistries": [
{
"kind": "osdu:wks:dataset--File.Generic:1.0.0",
"acl": {
"viewers": [
f"data.default.viewers@{osdu_partition}.example.com"
],
"owners": [
f"data.default.owners@{osdu_partition}.example.com"
]
},
"legal": {
"legaltags": [
f"{osdu_partition}-public-usa-dataset"
],
"otherRelevantDataCountries": [
"US"
],
"status": "compliant"
},
"data": {
"Description":"This is a test dataset uploaded by " + user_name,
"DatasetProperties": {
"FileSourceInfo": {
"FileSource": fileSource1
}
}
},
"meta": [],
"tags": {}
},
{
"kind": "osdu:wks:dataset--File.Generic:1.0.0",
"acl": {
"viewers": [
f"data.default.viewers@{osdu_partition}.example.com"
],
"owners": [
f"data.default.owners@{osdu_partition}.example.com"
]
},
"legal": {
"legaltags": [
f"{osdu_partition}-public-usa-dataset"
],
"otherRelevantDataCountries": [
"US"
],
"status": "compliant"
},
"data": {
"Description":"This is a test dataset uploaded by " + user_name,
"DatasetProperties": {
"FileSourceInfo": {
"FileSource": fileSource2
}
}
},
"meta": [],
"tags": {}
}
]
})
OSDU Register URL
The osdu_platform_url below is specific to the bootcamp
osdu_register_dataset_url = osdu_platform_url + '/api/dataset/v1/registerDataset/'
print(osdu_register_dataset_url)
Register dataset and print the result
Register dataset and print the result. API call returns the ID of our newly registered dataset.
response = requests.put(osdu_register_dataset_url, data=new_dataset, headers=headers)
print(json.dumps(response.json(), indent=4))
dataset_ids = [response.json()["datasetRegistries"][0]["id"], response.json()["datasetRegistries"][1]["id"]]
print(dataset_ids)
Retrieving the file
Let’s retrieve our file to make sure its there
body = {
"datasetRegistryIds": dataset_ids
}
osdu_retrieve_url = osdu_platform_url + '/api/dataset/v1/retrievalInstructions'
print(osdu_retrieve_url)
response = requests.post(osdu_retrieve_url, json=body, headers=headers)
print(json.dumps(response.json(), indent=4))
print(response.json()["datasets"][0]["retrievalProperties"]["signedUrl"])
print(response.json()["datasets"][1]["retrievalProperties"]["signedUrl"])
Lab complete
Congratulations! You have completed this lab!